How to Make Your Product The Ferrari Of Deepseek
페이지 정보

본문
 The US-China tech competition lies on the intersection of markets and nationwide security, and understanding how DeepSeek emerged from China’s excessive-tech innovation panorama can higher equip US policymakers to confront China’s ambitions for global technology leadership. This normally involves storing so much of data, Key-Value cache or or KV cache, temporarily, which will be gradual and memory-intensive. I'm wondering if this strategy would help a lot of these sorts of questions? Multi-Head Latent Attention (MLA): In a Transformer, consideration mechanisms help the model give attention to the most relevant elements of the input. However, such a posh large mannequin with many concerned components nonetheless has several limitations. DeepSeekMoE is a complicated model of the MoE architecture designed to improve how LLMs handle complex tasks. Complexity varies from on a regular basis programming (e.g. easy conditional statements and loops), to seldomly typed highly advanced algorithms which can be still reasonable (e.g. the Knapsack problem). Upcoming versions of DevQualityEval will introduce more official runtimes (e.g. Kubernetes) to make it simpler to run evaluations by yourself infrastructure. If you are curious about becoming a member of our improvement efforts for the DevQualityEval benchmark: Great, let’s do it!
The US-China tech competition lies on the intersection of markets and nationwide security, and understanding how DeepSeek emerged from China’s excessive-tech innovation panorama can higher equip US policymakers to confront China’s ambitions for global technology leadership. This normally involves storing so much of data, Key-Value cache or or KV cache, temporarily, which will be gradual and memory-intensive. I'm wondering if this strategy would help a lot of these sorts of questions? Multi-Head Latent Attention (MLA): In a Transformer, consideration mechanisms help the model give attention to the most relevant elements of the input. However, such a posh large mannequin with many concerned components nonetheless has several limitations. DeepSeekMoE is a complicated model of the MoE architecture designed to improve how LLMs handle complex tasks. Complexity varies from on a regular basis programming (e.g. easy conditional statements and loops), to seldomly typed highly advanced algorithms which can be still reasonable (e.g. the Knapsack problem). Upcoming versions of DevQualityEval will introduce more official runtimes (e.g. Kubernetes) to make it simpler to run evaluations by yourself infrastructure. If you are curious about becoming a member of our improvement efforts for the DevQualityEval benchmark: Great, let’s do it!
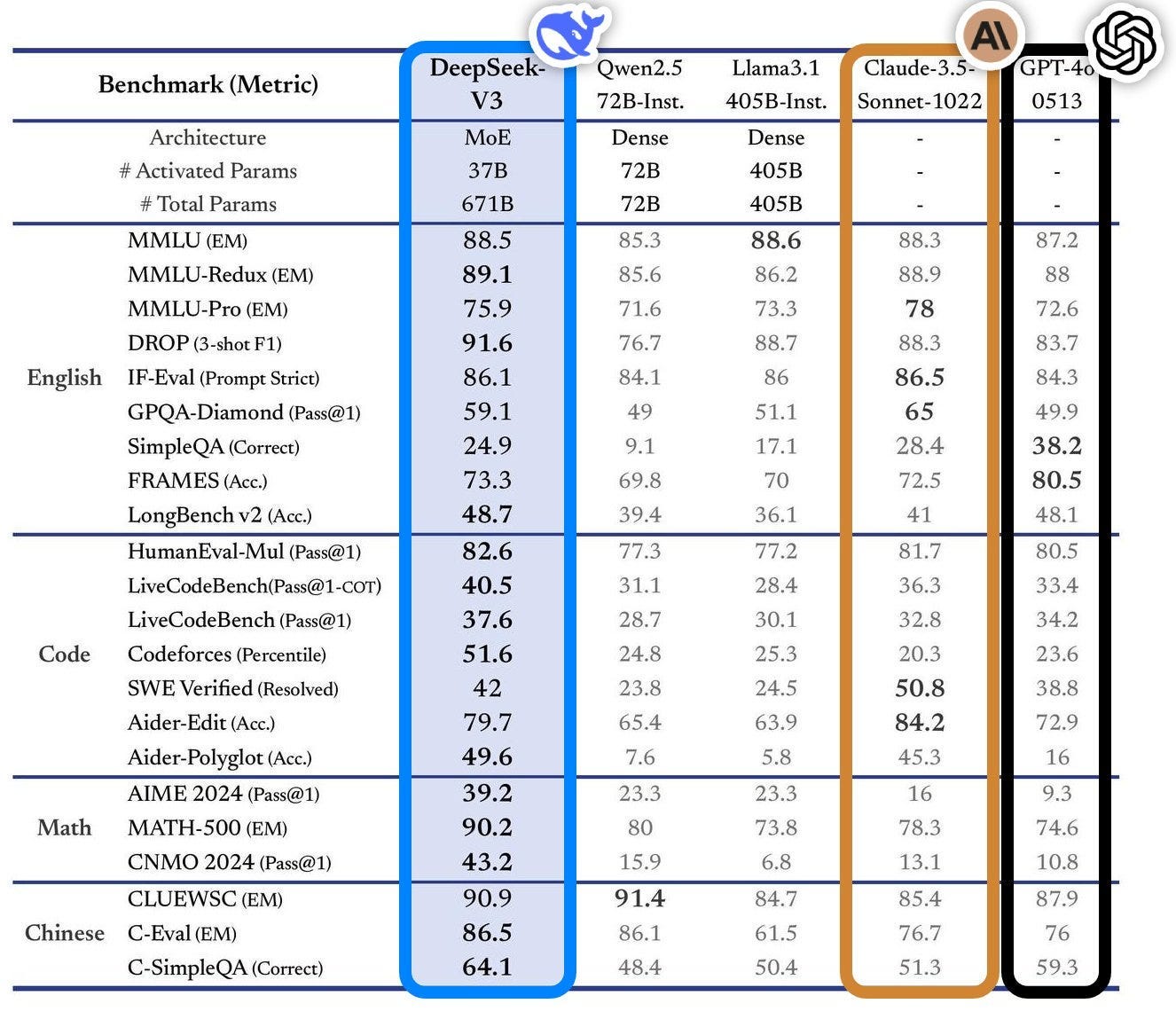 Let’s discover the particular models within the DeepSeek family and the way they manage to do all the above. Let’s take a look on the advantages and limitations. It’s educated on 60% source code, 10% math corpus, and 30% natural language. What's behind DeepSeek-Coder-V2, making it so special to beat GPT4-Turbo, Claude-3-Opus, Gemini-1.5-Pro, Llama-3-70B and Codestral in coding and math? DeepSeek-Coder-V2, costing 20-50x occasions lower than different models, represents a big upgrade over the original DeepSeek-Coder, with extra intensive coaching knowledge, bigger and extra environment friendly models, enhanced context handling, and advanced methods like Fill-In-The-Middle and Reinforcement Learning. Training data: Compared to the unique DeepSeek-Coder, DeepSeek-Coder-V2 expanded the coaching knowledge significantly by including a further 6 trillion tokens, rising the entire to 10.2 trillion tokens.
Let’s discover the particular models within the DeepSeek family and the way they manage to do all the above. Let’s take a look on the advantages and limitations. It’s educated on 60% source code, 10% math corpus, and 30% natural language. What's behind DeepSeek-Coder-V2, making it so special to beat GPT4-Turbo, Claude-3-Opus, Gemini-1.5-Pro, Llama-3-70B and Codestral in coding and math? DeepSeek-Coder-V2, costing 20-50x occasions lower than different models, represents a big upgrade over the original DeepSeek-Coder, with extra intensive coaching knowledge, bigger and extra environment friendly models, enhanced context handling, and advanced methods like Fill-In-The-Middle and Reinforcement Learning. Training data: Compared to the unique DeepSeek-Coder, DeepSeek-Coder-V2 expanded the coaching knowledge significantly by including a further 6 trillion tokens, rising the entire to 10.2 trillion tokens.
- 이전글Five Killer Quora Answers On Replacing Guttering And Downpipes 25.02.07
- 다음글5 Killer Quora Answers On Double Glazing Repairs Maidstone 25.02.07
댓글목록
등록된 댓글이 없습니다.