Do not Deepseek Except You employ These 10 Instruments
페이지 정보

본문
DeepSeek tells a joke about US Presidents Biden and Trump, but refuses to tell a joke about Chinese President Xi Jinping. If you’re feeling lazy, inform it to offer you three potential story branches at each flip, and also you choose probably the most interesting. Well, you’re in the correct place to find out! Whether you’re signing up for the first time or logging in as an present consumer, this information offers all the knowledge you need for a clean expertise. The byte pair encoding tokenizer used for Llama 2 is pretty normal for language models, and has been used for a fairly very long time. This seemingly innocuous mistake may very well be proof - a smoking gun per se - that, sure, deepseek ai china was skilled on OpenAI models, as has been claimed by OpenAI, and that when pushed, it can dive again into that coaching to talk its reality. Another company closely affected by DeepSeek is ChatGPT creator OpenAI. On 20 January 2025, DeepSeek launched free deepseek-R1 and DeepSeek-R1-Zero. DeepSeek-R1. Released in January 2025, this mannequin is predicated on DeepSeek-V3 and is focused on advanced reasoning duties directly competing with OpenAI's o1 mannequin in efficiency, whereas maintaining a significantly lower cost construction.
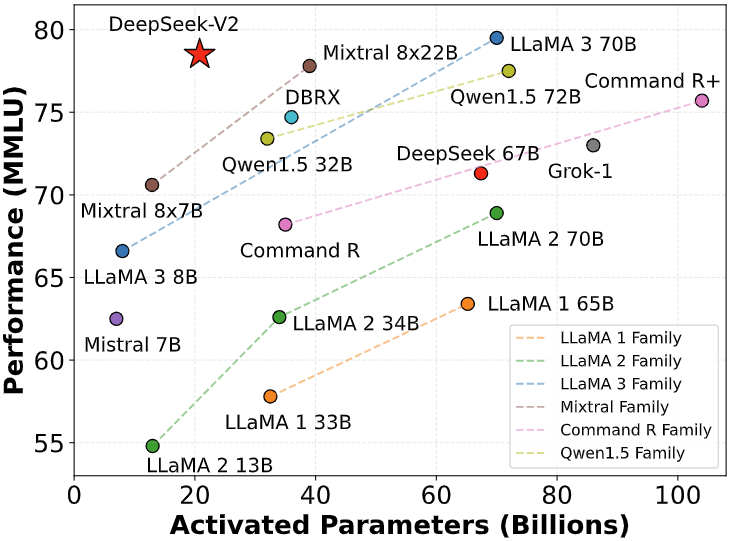 Also, I see individuals compare LLM energy utilization to Bitcoin, however it’s value noting that as I talked about in this members’ publish, Bitcoin use is tons of of times more substantial than LLMs, and a key difference is that Bitcoin is essentially built on using more and more power over time, whereas LLMs will get extra efficient as know-how improves. Falstaff’s blustering antics. Talking to historical figures has been instructional: The character says one thing unexpected, I look it up the old style way to see what it’s about, then learn something new. However, one undertaking does look a little bit extra official - the worldwide DePIN Chain. However, ديب سيك The Wall Street Journal stated when it used 15 problems from the 2024 version of AIME, the o1 model reached a solution sooner than DeepSeek-R1-Lite-Preview. However, small context and poor code technology stay roadblocks, and that i haven’t but made this work successfully. Third, LLMs are poor programmers. It may be helpful to determine boundaries - tasks that LLMs positively can not do.
Also, I see individuals compare LLM energy utilization to Bitcoin, however it’s value noting that as I talked about in this members’ publish, Bitcoin use is tons of of times more substantial than LLMs, and a key difference is that Bitcoin is essentially built on using more and more power over time, whereas LLMs will get extra efficient as know-how improves. Falstaff’s blustering antics. Talking to historical figures has been instructional: The character says one thing unexpected, I look it up the old style way to see what it’s about, then learn something new. However, one undertaking does look a little bit extra official - the worldwide DePIN Chain. However, ديب سيك The Wall Street Journal stated when it used 15 problems from the 2024 version of AIME, the o1 model reached a solution sooner than DeepSeek-R1-Lite-Preview. However, small context and poor code technology stay roadblocks, and that i haven’t but made this work successfully. Third, LLMs are poor programmers. It may be helpful to determine boundaries - tasks that LLMs positively can not do.
This balanced method ensures that the mannequin excels not only in coding tasks but in addition in mathematical reasoning and normal language understanding. By preventing the mannequin from overfitting on repetitive knowledge, it enhances efficiency on new and various coding duties. Normally, such inner data is shielded, stopping customers from understanding the proprietary or external datasets leveraged to optimize efficiency. Released in May 2024, this model marks a new milestone in AI by delivering a robust mixture of efficiency, scalability, and excessive efficiency. We adopt the BF16 data format as an alternative of FP32 to track the first and second moments within the AdamW (Loshchilov and Hutter, 2017) optimizer, without incurring observable efficiency degradation. Notably, it is the first open research to validate that reasoning capabilities of LLMs might be incentivized purely through RL, without the necessity for SFT. The past 2 years have also been nice for research. What role do we've over the development of AI when Richard Sutton’s "bitter lesson" of dumb strategies scaled on huge computers carry on working so frustratingly effectively? The info is also doubtlessly extra sensitive as well. This work-around is more expensive and requires extra technical know-how than accessing the mannequin by way of DeepSeek’s app or website.
 The choice between the 2 depends upon the user’s specific needs and technical capabilities. The difference here is pretty subtle: in case your mean is 0 then these two are precisely equal. There are various utilities in llama.cpp, however this text is anxious with just one: llama-server is this system you wish to run. There are instruments like retrieval-augmented generation and superb-tuning to mitigate it… In the face of disruptive applied sciences, moats created by closed supply are temporary. LLMs are fun, however what the productive makes use of do they have? Case in point: Recall how "GGUF" doesn’t have an authoritative definition. Reports in the media and discussions throughout the AI neighborhood have raised issues about DeepSeek exhibiting political bias. You'll find it by looking Actions ➨ AI: Text Generation ➨ DeepSeek Coder 6.7B Base AWQ Prompt (Preview). This relative openness additionally means that researchers all over the world are actually able to peer beneath the model's bonnet to search out out what makes it tick, in contrast to OpenAI's o1 and o3 that are successfully black containers.
The choice between the 2 depends upon the user’s specific needs and technical capabilities. The difference here is pretty subtle: in case your mean is 0 then these two are precisely equal. There are various utilities in llama.cpp, however this text is anxious with just one: llama-server is this system you wish to run. There are instruments like retrieval-augmented generation and superb-tuning to mitigate it… In the face of disruptive applied sciences, moats created by closed supply are temporary. LLMs are fun, however what the productive makes use of do they have? Case in point: Recall how "GGUF" doesn’t have an authoritative definition. Reports in the media and discussions throughout the AI neighborhood have raised issues about DeepSeek exhibiting political bias. You'll find it by looking Actions ➨ AI: Text Generation ➨ DeepSeek Coder 6.7B Base AWQ Prompt (Preview). This relative openness additionally means that researchers all over the world are actually able to peer beneath the model's bonnet to search out out what makes it tick, in contrast to OpenAI's o1 and o3 that are successfully black containers.
- 이전글우리의 가치와 신념: 삶의 지침 25.02.12
- 다음글4 Dirty Little Secrets About Upvc Door Panel And The Upvc Door Panel Industry 25.02.12
댓글목록
등록된 댓글이 없습니다.