The Advantages of Various Kinds Of Deepseek
페이지 정보

본문
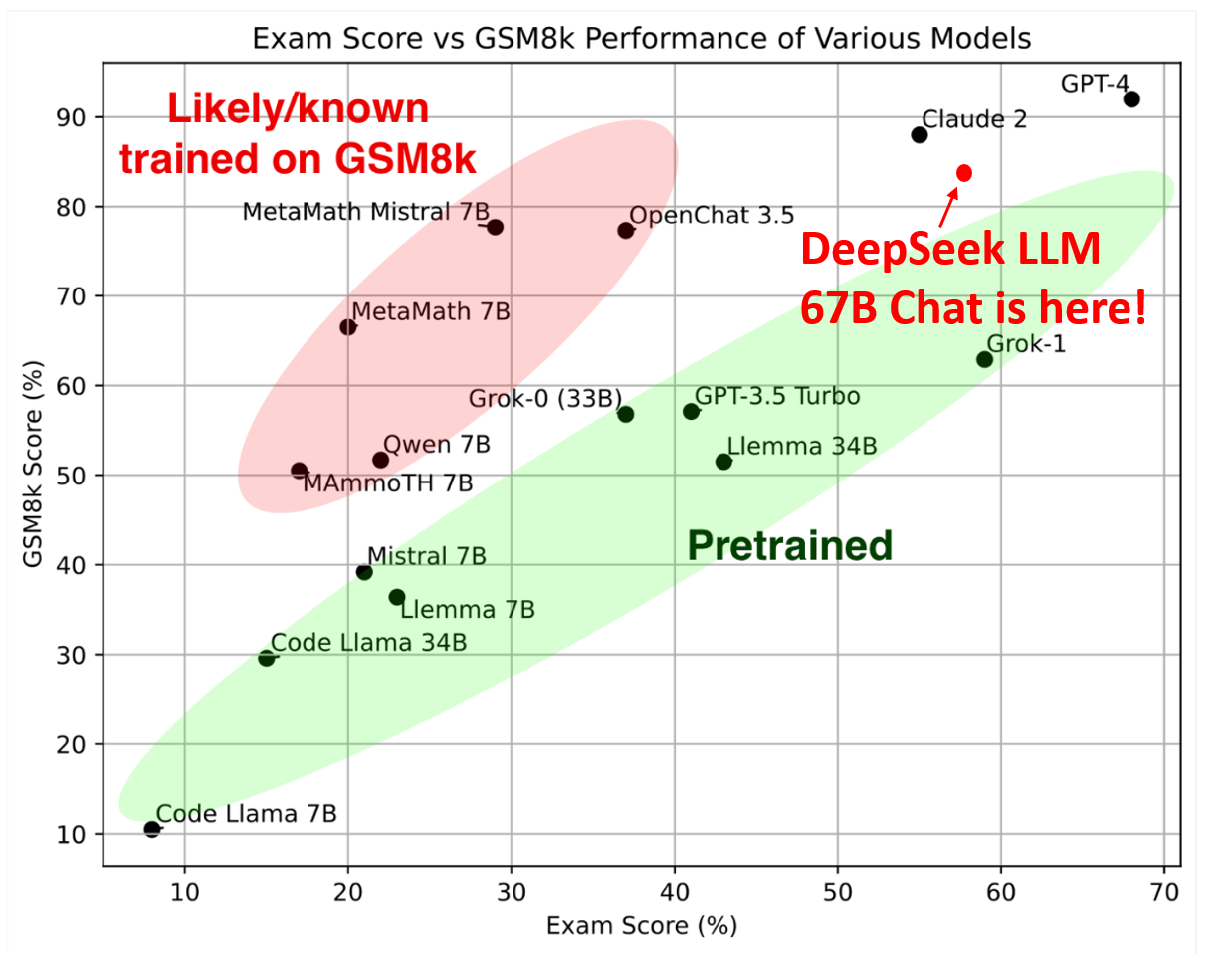 DeepSeek is a text mannequin. To further investigate the correlation between this flexibility and the advantage in mannequin efficiency, we additionally design and validate a batch-wise auxiliary loss that encourages load balance on each coaching batch instead of on each sequence. Parameter efficiency: DeepSeek’s MoE design activates solely 37 billion of its 671 billion parameters at a time. Additionally, DeepSeek’s ability to integrate with multiple databases ensures that customers can entry a big selection of data from different platforms seamlessly. The DeepSeek App AI is the direct conduit to accessing the advanced capabilities of the DeepSeek AI, a reducing-edge synthetic intelligence system developed to reinforce digital interactions across varied platforms. The convergence of rising AI capabilities and security concerns could create unexpected opportunities for U.S.-China coordination, whilst competitors between the nice powers intensifies globally. DeepSeek-R1 is the corporate's newest model, focusing on superior reasoning capabilities. As businesses and developers seek to leverage AI more effectively, DeepSeek-AI’s newest launch positions itself as a top contender in both normal-purpose language tasks and specialized coding functionalities. DeepSeek claims its latest model’s efficiency is on par with that of American AI leaders like OpenAI, and was reportedly developed at a fraction of the fee.
DeepSeek is a text mannequin. To further investigate the correlation between this flexibility and the advantage in mannequin efficiency, we additionally design and validate a batch-wise auxiliary loss that encourages load balance on each coaching batch instead of on each sequence. Parameter efficiency: DeepSeek’s MoE design activates solely 37 billion of its 671 billion parameters at a time. Additionally, DeepSeek’s ability to integrate with multiple databases ensures that customers can entry a big selection of data from different platforms seamlessly. The DeepSeek App AI is the direct conduit to accessing the advanced capabilities of the DeepSeek AI, a reducing-edge synthetic intelligence system developed to reinforce digital interactions across varied platforms. The convergence of rising AI capabilities and security concerns could create unexpected opportunities for U.S.-China coordination, whilst competitors between the nice powers intensifies globally. DeepSeek-R1 is the corporate's newest model, focusing on superior reasoning capabilities. As businesses and developers seek to leverage AI more effectively, DeepSeek-AI’s newest launch positions itself as a top contender in both normal-purpose language tasks and specialized coding functionalities. DeepSeek claims its latest model’s efficiency is on par with that of American AI leaders like OpenAI, and was reportedly developed at a fraction of the fee.
 These claims still had a massive pearl-clutching effect on the inventory market. This twin deal with autonomous automobiles and AI advancement makes Baidu a compelling tech inventory to observe in 2025, as it strengthens its position in two of expertise's most promising frontiers. TLDR: China is benefiting from offering free Deep seek AI by attracting a large consumer base, refining their technology based on consumer suggestions, probably setting international AI requirements, accumulating precious data, creating dependency on their tools, and challenging major tech corporations. At the same time, some companies are banning DeepSeek, and so are whole nations and governments, together with South Korea. Which brings us back to the radiation studying off San Diego, 647 miles or so to the SOUTH of the earthquake location. Crated a simple Flask Python app that basically can handle incoming API calls (sure, it has authorization) with a prompt, then triggers a LLM and reply back. Rather a lot can go mistaken even for such a easy instance. Step 2: Enter your question in the search field, try to use full sentences or questions so that the system can higher perceive what you mean.
These claims still had a massive pearl-clutching effect on the inventory market. This twin deal with autonomous automobiles and AI advancement makes Baidu a compelling tech inventory to observe in 2025, as it strengthens its position in two of expertise's most promising frontiers. TLDR: China is benefiting from offering free Deep seek AI by attracting a large consumer base, refining their technology based on consumer suggestions, probably setting international AI requirements, accumulating precious data, creating dependency on their tools, and challenging major tech corporations. At the same time, some companies are banning DeepSeek, and so are whole nations and governments, together with South Korea. Which brings us back to the radiation studying off San Diego, 647 miles or so to the SOUTH of the earthquake location. Crated a simple Flask Python app that basically can handle incoming API calls (sure, it has authorization) with a prompt, then triggers a LLM and reply back. Rather a lot can go mistaken even for such a easy instance. Step 2: Enter your question in the search field, try to use full sentences or questions so that the system can higher perceive what you mean.
We mechanically acquire certain information from you when you use the Services, together with internet or other network exercise information reminiscent of your IP address, unique system identifiers, and cookies. 조금만 더 이야기해 보면, 어텐션의 기본 아이디어가 ‘디코더가 출력 단어를 예측하는 각 시점마다 인코더에서의 전체 입력을 다시 한 번 참고하는 건데, 이 때 모든 입력 단어를 동일한 비중으로 고려하지 않고 해당 시점에서 예측해야 할 단어와 관련있는 입력 단어 부분에 더 집중하겠다’는 겁니다. 소스 코드 60%, 수학 코퍼스 (말뭉치) 10%, 자연어 30%의 비중으로 학습했는데, 약 1조 2천억 개의 코드 토큰은 깃허브와 CommonCrawl로부터 수집했다고 합니다. 마이크로소프트 리서치에서 개발한 것인데, 주로 수학 이론을 형식화하는데 많이 쓰인다고 합니다. 위에서 ‘DeepSeek-Coder-V2가 코딩과 수학 분야에서 GPT4-Turbo를 능가한 최초의 오픈소스 모델’이라고 말씀드렸는데요. 이 Lean 4 환경에서 각종 정리의 증명을 하는데 사용할 수 있는 최신 오픈소스 모델이 DeepSeek-Prover-V1.5입니다. DeepSeek 연구진이 고안한 이런 독자적이고 혁신적인 접근법들을 결합해서, DeepSeek-V2가 다른 오픈소스 모델들을 앞서는 높은 성능과 효율성을 달성할 수 있게 되었습니다. DeepSeek-V2는 위에서 설명한 혁신적인 MoE 기법과 더불어 DeepSeek 연구진이 고안한 MLA (Multi-Head Latent Attention)라는 구조를 결합한 트랜스포머 아키텍처를 사용하는 최첨단 언어 모델입니다. 이런 두 가지의 기법을 기반으로, DeepSeekMoE는 모델의 효율성을 한층 개선, 특히 대규모의 데이터셋을 처리할 때 다른 MoE 모델보다도 더 좋은 성능을 달성할 수 있습니다. MoE에서 ‘라우터’는 특정한 정보, 작업을 처리할 전문가(들)를 결정하는 메커니즘인데, 가장 적합한 전문가에게 데이터를 전달해서 각 작업이 모델의 가장 적합한 부분에 의해서 처리되도록 하는 것이죠.
기존의 MoE 아키텍처는 게이팅 메커니즘 (Sparse Gating)을 사용해서 각각의 입력에 가장 관련성이 높은 전문가 모델을 선택하는 방식으로 여러 전문가 모델 간에 작업을 분할합니다. DeepSeekMoE는 LLM이 복잡한 작업을 더 잘 처리할 수 있도록 위와 같은 문제를 개선하는 방향으로 설계된 MoE의 고도화된 버전이라고 할 수 있습니다. DeepSeek-Coder-V2는 컨텍스트 길이를 16,000개에서 128,000개로 확장, 훨씬 더 크고 복잡한 프로젝트도 작업할 수 있습니다 - 즉, 더 광범위한 코드 베이스를 더 잘 이해하고 관리할 수 있습니다. 이런 방식으로 코딩 작업에 있어서 개발자가 선호하는 방식에 더 정교하게 맞추어 작업할 수 있습니다. DeepSeek-V2에서 도입한 MLA라는 구조는 이 어텐션 메커니즘을 변형해서 KV 캐시를 아주 작게 압축할 수 있게 한 거고, 그 결과 모델이 정확성을 유지하면서도 정보를 훨씬 빠르게, 더 적은 메모리를 가지고 처리할 수 있게 되는 거죠. 이렇게 하면, 모델이 데이터의 다양한 측면을 좀 더 효과적으로 처리할 수 있어서, 대규모 작업의 효율성, 확장성이 개선되죠. DeepSeekMoE는 각 전문가를 더 작고, 더 집중된 기능을 하는 부분들로 세분화합니다. 이전 버전인 DeepSeek-Coder의 메이저 업그레이드 버전이라고 할 수 있는 DeepSeek-Coder-V2는 이전 버전 대비 더 광범위한 트레이닝 데이터를 사용해서 훈련했고, ‘Fill-In-The-Middle’이라든가 ‘강화학습’ 같은 기법을 결합해서 사이즈는 크지만 높은 효율을 보여주고, 컨텍스트도 더 잘 다루는 모델입니다. 거의 한 달에 한 번 꼴로 새로운 모델 아니면 메이저 업그레이드를 출시한 셈이니, 정말 놀라운 속도라고 할 수 있습니다. DeepSeek-Coder-V2 모델은 컴파일러와 테스트 케이스의 피드백을 활용하는 GRPO (Group Relative Policy Optimization), 코더를 파인튜닝하는 학습된 리워드 모델 등을 포함해서 ‘정교한 강화학습’ 기법을 활용합니다.
- 이전글20 Fun Facts About Doors With Windows 25.03.07
- 다음글The 10 Most Terrifying Things About Order Fake Currency 25.03.07
댓글목록
등록된 댓글이 없습니다.