Deepseek Promotion one hundred and one
페이지 정보

본문
 It’s called DeepSeek R1, and it’s rattling nerves on Wall Street. He’d let the car publicize his location and so there were people on the road taking a look at him as he drove by. These large language models have to load completely into RAM or VRAM each time they generate a new token (piece of text). For comparability, excessive-finish GPUs just like the Nvidia RTX 3090 boast nearly 930 GBps of bandwidth for his or her VRAM. GPTQ fashions profit from GPUs just like the RTX 3080 20GB, A4500, A5000, and the likes, demanding roughly 20GB of VRAM. Having CPU instruction units like AVX, AVX2, AVX-512 can further enhance performance if available. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free deepseek strategy for load balancing and sets a multi-token prediction coaching goal for stronger performance. Trained on 14.8 trillion numerous tokens and incorporating superior strategies like Multi-Token Prediction, DeepSeek v3 sets new requirements in AI language modeling. On this scenario, you possibly can expect to generate roughly 9 tokens per second. Send a test message like "hi" and examine if you will get response from the Ollama server.
It’s called DeepSeek R1, and it’s rattling nerves on Wall Street. He’d let the car publicize his location and so there were people on the road taking a look at him as he drove by. These large language models have to load completely into RAM or VRAM each time they generate a new token (piece of text). For comparability, excessive-finish GPUs just like the Nvidia RTX 3090 boast nearly 930 GBps of bandwidth for his or her VRAM. GPTQ fashions profit from GPUs just like the RTX 3080 20GB, A4500, A5000, and the likes, demanding roughly 20GB of VRAM. Having CPU instruction units like AVX, AVX2, AVX-512 can further enhance performance if available. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free deepseek strategy for load balancing and sets a multi-token prediction coaching goal for stronger performance. Trained on 14.8 trillion numerous tokens and incorporating superior strategies like Multi-Token Prediction, DeepSeek v3 sets new requirements in AI language modeling. On this scenario, you possibly can expect to generate roughly 9 tokens per second. Send a test message like "hi" and examine if you will get response from the Ollama server.
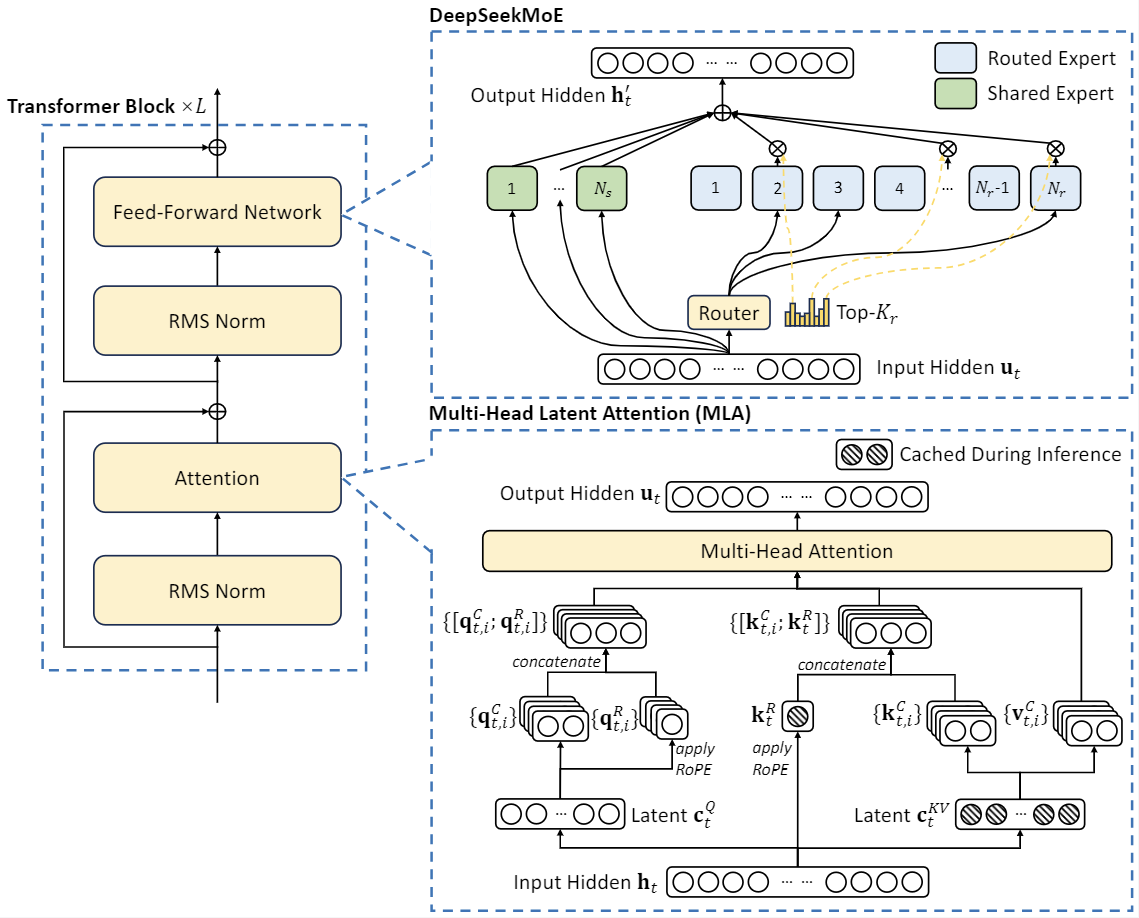
If you don't have Ollama put in, check the previous weblog. You should utilize that menu to talk with the Ollama server with out needing an internet UI. You can launch a server and query it utilizing the OpenAI-suitable imaginative and prescient API, which supports interleaved text, multi-picture, and video formats. Explore all variations of the mannequin, their file codecs like GGML, GPTQ, and HF, and perceive the hardware requirements for local inference. If you are venturing into the realm of bigger models the hardware requirements shift noticeably. The efficiency of an Deepseek model relies upon heavily on the hardware it's running on. Note: Unlike copilot, we’ll focus on regionally operating LLM’s. Multi-Head Latent Attention (MLA): In a Transformer, attention mechanisms assist the model concentrate on probably the most relevant components of the input. If your system doesn't have quite enough RAM to totally load the model at startup, you may create a swap file to assist with the loading. RAM wanted to load the mannequin initially. Suppose your have Ryzen 5 5600X processor and DDR4-3200 RAM with theoretical max bandwidth of fifty GBps. An Intel Core i7 from 8th gen onward or AMD Ryzen 5 from 3rd gen onward will work well. The GTX 1660 or 2060, AMD 5700 XT, or RTX 3050 or 3060 would all work properly.
For Best Performance: Opt for a machine with a excessive-end GPU (like NVIDIA's newest RTX 3090 or RTX 4090) or dual GPU setup to accommodate the biggest fashions (65B and 70B). A system with ample RAM (minimal sixteen GB, but 64 GB finest) would be optimum. For suggestions on the perfect laptop hardware configurations to handle Deepseek fashions easily, check out this guide: Best Computer for Running LLaMA and LLama-2 Models. But, if an concept is effective, it’ll find its manner out simply because everyone’s going to be speaking about it in that really small neighborhood. Emotional textures that humans find fairly perplexing. Within the fashions checklist, add the fashions that put in on the Ollama server you want to use within the VSCode. Open the listing with the VSCode. Without specifying a specific context, it’s important to notice that the precept holds true in most open societies but doesn't universally hold throughout all governments worldwide. It’s significantly extra efficient than different models in its class, will get great scores, and the research paper has a bunch of particulars that tells us that DeepSeek has built a group that deeply understands the infrastructure required to train ambitious models.
When you look nearer at the outcomes, it’s value noting these numbers are closely skewed by the easier environments (BabyAI and Crafter). This mannequin marks a considerable leap in bridging the realms of AI and excessive-definition visual content material, offering unprecedented alternatives for professionals in fields the place visible element and accuracy are paramount. For instance, a system with DDR5-5600 providing around 90 GBps may very well be enough. This means the system can better perceive, generate, and edit code compared to previous approaches. But perhaps most considerably, buried within the paper is an important insight: you possibly can convert just about any LLM into a reasoning model in the event you finetune them on the precise mix of data - right here, 800k samples displaying questions and answers the chains of thought written by the model while answering them. Flexing on how a lot compute you've gotten entry to is common apply among AI companies. After weeks of focused monitoring, we uncovered a much more vital risk: a notorious gang had begun purchasing and wearing the company’s uniquely identifiable apparel and utilizing it as a symbol of gang affiliation, posing a significant threat to the company’s image by way of this adverse association.
- 이전글인생의 퍼즐: 어려움을 맞닥뜨리다 25.02.01
- 다음글Discover the Convenience of Fast and Easy Loans with EzLoan 25.02.01
댓글목록
등록된 댓글이 없습니다.